Reuse strategies and the mechanisms that support them
by France Baril
I reuse, you reuse, he/she reuses, we reuse, you reuse, they reuse… and yet most of us are doing it different ways and for different reasons. We want to increase consistency, save time, save money, adapt content to different users or contexts, provide support in a new output format, and more.
Then a standard like DITA comes along and its supporters pretend that it enables R-E-U-S-E. Congratulations! You have just come up with a standard that pretends to do the same thing that a lot of other tools and standards are pretending to do. What an innovation!
Well, the innovation may just come from the fact that DITA actually supports a lot of different reuse strategies by offering multiple mechanisms.
In this article, I want to share my understanding and use of these mechanisms, and I hope that through further discussion we can push the limits of what I have been able to put on paper. The main questions that I am addressing are:
- What are the different reuse strategies that DITA supports?
and
- When and how do we use each?
Creating multiple output types
What? The ability to deliver content in multiple output types, including the popular HTML and PDF formats.
When? When end users need to access the information through different media.
How? DITA is XML, and XML allows anyone to create multiple output types, provided that they have minimal XSL knowledge and/or the right toolset.
Filtering/conditional text
What? Filtering typically means to use conditions to filter segments in or out of an end deliverable. It is used to create, from a single source of content, outputs that contain only the information relevant to specific audiences, products, or other sub-groups.
When? When you need to hide information from some users or adapt content to different flavors of a product.
How? DITA filtering is done by setting the value of filtering attributes like audience, product, or platform. DITA 1.0 offers the <otherprops> attribute to allow users to extend the list of available filters, and DITA 1.1 offers the ability to create new attributes based on a specialization mechanism.
Generating content automatically
What? Automatic content creation is usually based on content extraction. Content may be extracted from external sources, like code or a database, or from various topic sections. It is mostly used for creating overviews, summaries, or API documentation.
When? When the rules that define where the content should come from and where it should go can be expressed clearly and be applied systematically without human intervention. This type of reuse relies on a well-defined information structure that enables systematic, planned reuse as opposed to opportunistic reuse where you decide on the spot that you’d like to reuse something written previously.
How? Automatic content creation is wide spread in its simplest form. Most tools can extract section titles (headings) to generate a table of contents (TOC). However, it is rarely exploited to its full potential.
XML eases content manipulation from the computing point of view. DITA allows the creation of content in a more semantically meaningful way. It defines what the content is, a short description or a task’s context as opposed to a paragraph, a concept as opposed to a section. DITA and XML put extra power in the hands of documentation teams.
Once elements are organized in a predictable structure, it is easy to know where information is located, to extract it, transform it, and then display it differently.
Here is an example, from an API documentation set, in which the class overviews are created from the methods’ short descriptions and the methods are documented by extracting content from the code itself and from the Web Services’ database.
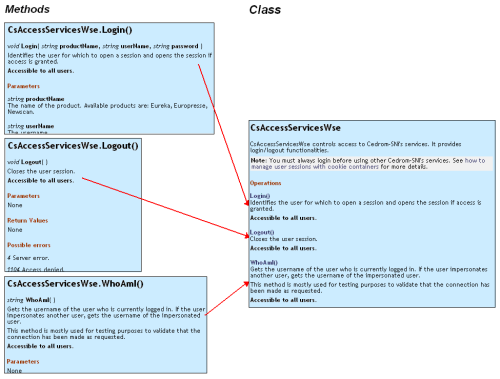
Since predictability is the most important factor in successful content generation, you should look for patterns in your documentation process or simply create them by developing guidelines for using the different elements available in DITA.
Referencing content from other topics
What? The reuse of a topic segment in another topic, where modifications to the original segment affect all topics that use it. Segments may be paragraphs, notes, and others.
When? When you use the same segment over and over again and when changes to the original segments should be applied to all topics that use the segments.
How? DITA provide a conref attribute to manage references from one segment to another. I’d like to suggest that the conref mechanism should be used on segments that make sense on their own, although they may not provide enough context to become topics. Notes and warnings are good examples: “Opening the box with a blade may damage the content” or the description of parameters used in multiple API methods: “The product name. Available products are…” Chances for someone to add a ‘Moreover’ that does not make sense in other contexts at the beginning of the original segment are low in these cases.
Using variables for words and phrases
What? A mechanism that allows one or a few words to be replaced by a specified value at a specific moment in time.
When? Variables are most often used when content is reused for different but very similar products. For example, you may want to use a variable to change the product name at will when the content applies to more then one product.
How? The technical specificity of the mechanisms can be diverse, but the basics are always the same. Put a tag somewhere that can be replaced at processing by a real value. Tip: Ask your localization team if changing the value of a variable may impact the sentences around it.
Repurposing or reusing content in different contexts
What? Reusing content in different contexts is probably the most tricky and hard to implement strategy. It implies adapting the content not just to show and hide information that might or might not be relevant to some audiences but also to present it in a way that adapts to the users’ cognitive processes, even if they are using the content for different purposes.
When? When adapting documentation to meet different user goals like taking content from a reference guide to create training manuals.
How? By applying one or more available mechanisms to transform content.
For example, in a reference guide, you might want to organize content by features to help users who have specific needs find what they are looking for. For example, they may want to:
- Know if something can be done;
- Find a specific system task;
- Be reminded how to perform a specific system task;
- Find shortcuts and alternatives.
However, people in training who are going to use the product for the first time might need to understand the main product goal and how the tasks relate to each other. Throwing a bunch of system task at them does not help them understand how to put them together to meet their objectives. They need to:
- Understand the purpose of the tooll
- See how tasks relate to each other and how they can be performed in a specific order to reach the primary goal;
- Apply the information to their day-to-day activities;
- Learn why a feature is interesting or what does it does for them;
- Understand workflow.
The following image illustrates how topics that document how to use a Content Management System can be reorganized to serve as a reference guide or a training guide. Reorganizing the content usually implies creating a new map and leverages DITA’s modular topic model.
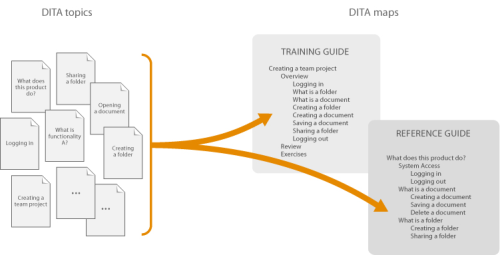
If you wanted to push this further, you could push linear tutorial examples into more then one topic of the training guide, in which you can ask the trainee to create a folder with a specific name ‘My Project’ and then in a later topic to save a document in the folder called ‘My Project’.
Sometimes, you may have to develop your own processes to achieve your final goal.
Open questions for further discussion
This summarizes my reuse experiences with DITA. Now it’s your turn…
Are some strategies really better to meet specific objectives? Can DITA with its modular flexibility bridge the gap between reference content creators and instructional designers? Have I forgotten important reuse strategies?
Share your perspective on this article with author, France Baril, and see what others think in our Reuse Strategies forum. Also weigh in on our poll.