DITA
[Early Bird Conference Discount] ConVEx 2026 Pittsburgh
The Center for Information Development Management (CIDM) brings its annual content development conference, ConVEx, to Pittsburgh, PA, April 13-15, 2026. You can save $300 if you register before the end of the year (end of day December 31, 2025).

In its 28th year, this event offers a wealth of ideas and information to support your efforts in defining and executing a comprehensive content strategy. ConVEx offers a great opportunity to learn, connect, and share ideas with others in the technical documentation and content strategy community and gives you a rare insider’s look at what is working (or not) for other teams.
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Why 95% of GenAI Pilots Fail (and What Tech Writers Can Do About It)
95% of corporate generative-AI pilots are failing.
If that number surprises you, congratulations on being new to enterprise life. For everyone else — especially technical writers — it confirms what we suspected the moment someone said, “Let’s try AI! How hard could it be?”
The MIT report points to poorly prepared content, vague business goals, and content governance practices so thin you could blow on them and watch them evaporate. And underneath it all sits a truth tech writers have muttered for years: most companies are shoveling unstructured, inconsistent, poorly labeled content into AI systems and hoping for miracles.
Below is what the research found — and what technical writers can do before someone declares another AI pilot a “learning experience.”

AI Fails When Content Has the Structural Integrity of a Half-Melted Snowman
According to the MIT findings, companies toss PDFs, wikis, slide decks, and assorted mystery documents into AI tools and expect reliable answers. That’s like expecting a Michelin-star meal when the only ingredients you brought home from the grocery store are two bruised bananas and a packet of oyster crackers.
AI needs:
Structure
Clarity
Metadata
Version control
Consistent terminology
Without those, LLMs do what humans do in the same situation—guess. Badly.
Technical writers have been preaching this for decades. We knew “throw content at it and hope for the best” was not a scalable strategy long before generative AI became the world’s favorite shiny object.

Companies Launch AI Pilots the Way People Start Diets: With Enthusiasm and No Plan
The research highlights another classic pattern: teams rush into AI because someone heard about “transformational value” during a keynote, but nobody paused to ask basic questions like:
What problem are we solving?
Is our source content consistent?
Do we even know where all our content lives?
Should we fix any of this before building the future?
By skipping content operations, organizations create pilots destined to fail — pilots that cost money, time, and at least three internal presentations where someone says “synergy” without irony.
Technical writers already build content inventories, style guides, taxonomies, and structured authoring environments. If companies involved writers earlier, they’d spend less time reporting pilot failures and more time scaling successes.
Most Pilots Don’t Fail (They Never Had a Chance to Succeed)
The MIT report shows that many AI pilots were not designed with success criteria, governance, or production-grade content. They were designed with hope. And hope—while emotionally satisfying — is not an operational strategy.
When results disappoint, leaders blame “AI limitations,” rather than acknowledging the more awkward truth: the system relied on content that looked like it had been assembled by a committee that doesn’t speak to each other.
Technical writers can help fix that by:
Designing modular, machine-friendly content
Governing terminology
Adding metadata and structure
Creating models that support retrieval and reasoning
Partnering with AI, product, and engineering teams early
In short, writers provide the discipline AI needs but cannot request politely.

AI Will Only Work When Documentation Stops Being Treated Like Emotional Labor
The MIT research frames generative AI as a strategic asset that requires operational maturity. That maturity lives in documentation teams — teams who often get involved only after pilots collapse, like firefighters arriving to discover the house was built from paper mâché.
When AI becomes part of the product (fueling chatbots, search experiences, in-app guidance, and autonomous agents) technical writers move from “nice to have” to “everything collapses without you.”
This shift requires:
Content designed for both humans and machines
Clear models, terminology, and metadata
Rigorous governance
Collaboration across disciplines
AI won’t replace writers. But AI will absolutely expose who has been ignoring writers.

What Tech Writers Can Do Now (Beyond Mildly Smirking at the 95% Statistic)
Here are six steps writers can take—practical, empowering, and yes, slightly satisfying:
Build an authoritative inventory
Identify what’s trustworthy, what’s outdated, and what should be escorted off the premises.
Advocate for structured authoring
AI thrives on clean, modular, governed content. Chaos is not a data strategy.
Establish terminology
LLMs cannot magically intuit what your team calls things. Sometimes your team cannot intuit that either.
Create agent-friendly content models
Structure and metadata turn content from “text” into “knowledge.”
Partner early
If you’re invited late, ask for a time machine. Otherwise, insist on being embedded from the start.
Document limits
Telling AI what not to answer is just as important as telling it what to answer.

AI Isn’t the Problem—Your Content Operations Are
The headline statistic—95% failure—makes it sound like AI is misbehaving.
But the truth is simple: AI cannot succeed if the content behind it isn’t designed to support it.
Companies that invest in content operations, structured authoring, terminology governance, and documentation content strategy will see AI deliver real value.
Companies that don’t will keep running pilots whose primary output is disappointment.
Technical writers are the missing ingredient—not the afterthought. And unlike most AI pilots, that’s a story with a strong chance of success. 🤠
Free Course: Become an Explanation Specialist
We explain things constantly — at work, with friends, and in our closest relationships. Every one of us is an explainer.
But most of the time, our explanations just… happen. We fall back on habits we’ve carried for years. Some people naturally communicate with clarity. Others learned pieces of the skill in school or through experience. Many struggle. And everyone — every single one of us — can get better.
That’s where the Explainer Academy comes in.
In this free course from our friends at CommonCraft, I invite you to take a fresh look at how you communicate. You’ll see that explanation isn’t a fixed trait. It’s a skill you can sharpen. And because we explain things so often, even a small improvement can make a big difference. 🤠

The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Content Operations in the Age of Artificial Intelligence
80% of organizations are using AI, but only 29% report moderate or fast progress in scaling it.
That’s one of many insights from Content Science’s latest report about the world’s largest study of content operations. In this recorded webinar, Colleen Jones and Christopher Jones, PhD, delve into what the newest research with more than 100 professionals, leaders, and executives says about the current state of content operations—and what it means for you.
Watch the on-demand recording to:
• Learn about the promising shift to more mature content operations
• Understand the new obstacles to maturing content operations maturity today
• Gain insight into what the most successful organizations do differently
• Learn why maturing content operations is the secret to success with AI
• Gain perspective from leaders with top organizations such as ServiceNow, Akoya, Red Hat, and more
Why Traceability Matters in the Generative AI Age
As organizations adopt generative AI to help create, retrieve, or transform technical content, the need for traceability has become impossible to ignore. Writers, editors, and content strategists now live in a world where AI can draft a procedure, summarize a release note, or answer a customer’s question using your documentation. That convenience comes with a new responsibility: understanding how the system arrived at its answer.
👉🏼 This is where traceability comes in.

What Traceability Means in Generative AI
Traceability is the ability to follow the path from an AI-generated output back to the ingredients that produced it.
This includes:
Which source documents the system used
Which model or model version generated the response
What prompts or instructions shaped the output
Which agents or intermediate steps contributed
How the content was transformed along the way
👉🏼 Think of it as an audit trail for generative AI.
When someone asks, “Why did the system say this?”, traceability lets you respond with specifics instead of guesses.

Why Traceability Should Matter to Technical Writers
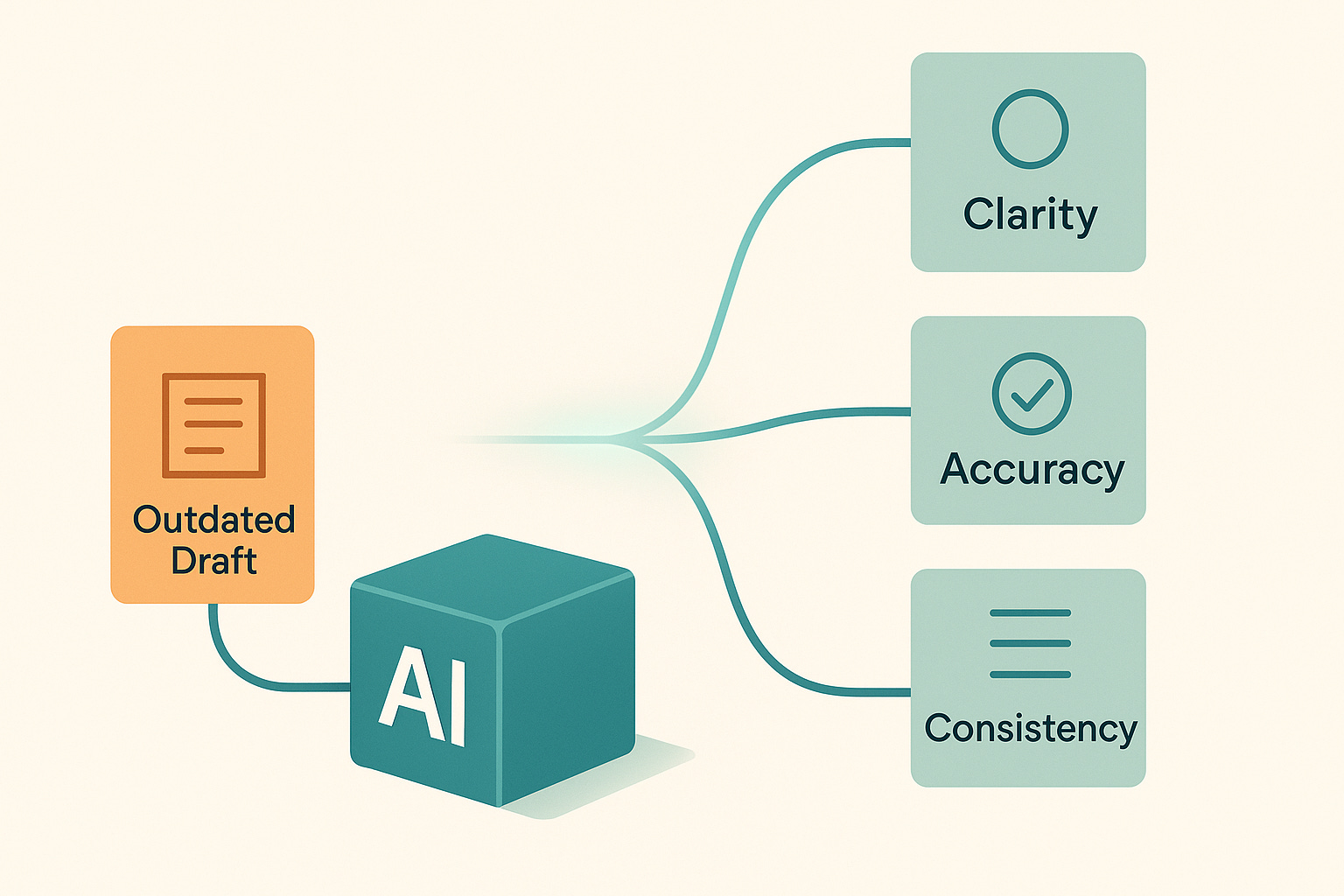
Technical writers are already responsible for clarity, accuracy, and consistency. Generative AI doesn’t change that — it amplifies it. When AI enters the workflow, writers must ensure the system uses the right source content and produces outputs that reflect the approved truth.
👉🏼 Traceability makes that possible.
With traceability, you can confirm whether an answer came from a vetted topic or from an outdated draft lurking in a forgotten folder. You can determine whether the system hallucinated a detail or faithfully retrieved information from your component content management system (CCMS). You can see which metadata tags influenced retrieval and whether an agent followed your instructions or drifted off course.
Without traceability, you’re left guessing — not a great position when accuracy is part of your job description.
The Role of Traceability in Governance and Compliance
Many writers work in environments where rules matter: medical devices, finance, transit, telecom, cybersecurity, manufacturing. In these contexts, every published statement must be backed by a controlled source.
Related: The Ultimate Guide to Becoming a Medical Device Technical Writer
As AI becomes part of content production, reviewers, auditors, and regulators will ask legitimate questions:
Was this answer based on approved documentation?
Did the system use any restricted content?
Can you prove the output followed the organization’s processes?
👉🏼 Traceability provides the evidence.
It becomes a natural extension of version control, metadata, review workflows, and other content governance practices writers already use.

Traceability Helps You Debug AI Systems
When a retrieval-augmented generation (RAG) system or an AI agent produces something incorrect, traceability tells you where the failure occurred.
Maybe the retrieval logic surfaced the wrong topic
Maybe the metadata on a source file was inaccurate
Maybe an AI agent misinterpreted the instruction chain
👉🏼 Traceability turns debugging into a structured process instead of a guessing game.
This matters for writers because you’re often the first person asked to evaluate whether an AI-generated answer is correct — and the first person blamed if it isn’t.
With traceability, you can pinpoint the issue, fix the source, and improve the system.
Protecting the Integrity of Your Documentation
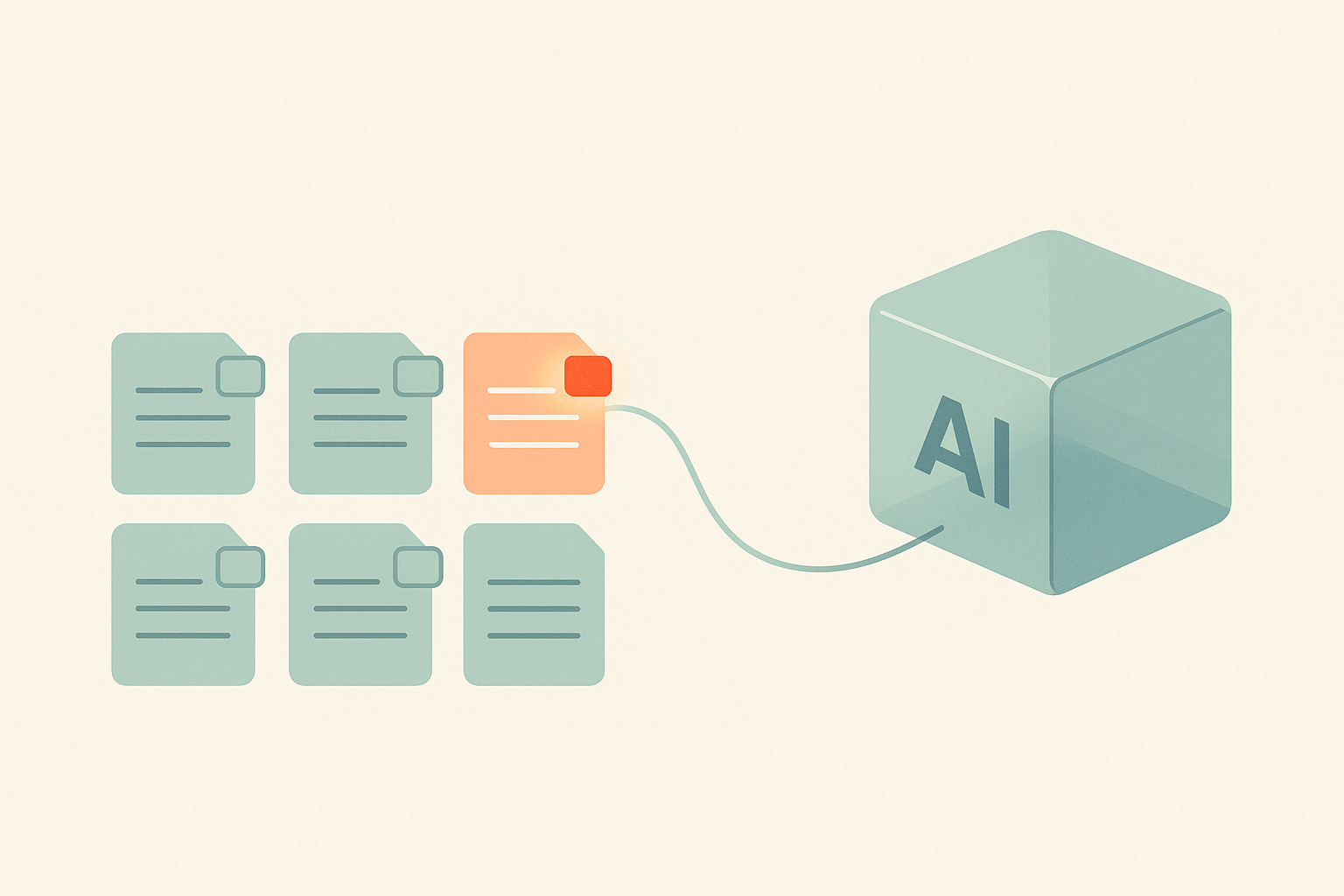
Writers spend years building controlled vocabularies, maintaining topic libraries, preserving intent, and making sure content stays consistent. Generative AI systems, by design, remix information. That remixing can introduce subtle distortions unless you can see which sources were used and how the system transformed them.
Traceability helps you catch:
Pulls from outdated drafts
Blends of two similar topics
Responses formed from misinterpreted metadata
Answers based on content that never passed review
👉🏼 It gives writers back the visibility they lose when AI systems automate pieces of the workflow.
Preparing for AI-Driven Content Operations
As CCMS platforms and documentation tools integrate AI, traceability will become part of the content lifecycle.
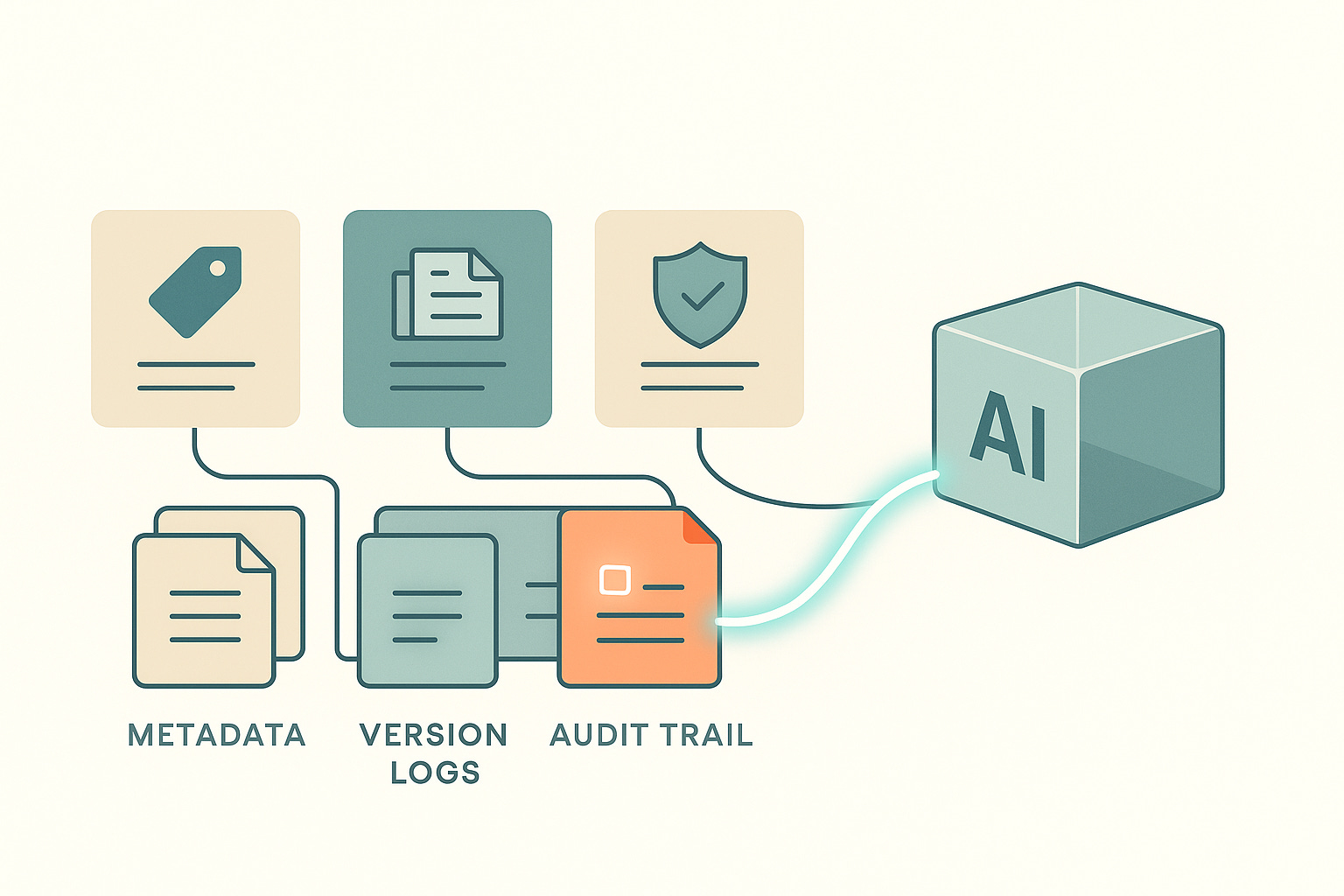
Future authoring and publishing workflows will include:
Metadata showing which topics influenced an AI-generated suggestion
Logs showing which versions of a topic were used
Audit trails showing how an AI assistant arrived at its edits or summaries
Review tools that highlight AI-originated content for approval
👉🏼 Writers who understand traceability will be positioned to help design these workflows, maintain the content behind them, and ensure trustworthy outputs.

What This Means for Technical Writers
Traceability is the safety layer that makes generative AI viable in professional documentation. It gives technical writers the ability to confirm accuracy, protect content integrity, debug AI behavior, and meet governance expectations.
Without it, AI becomes a black box — impressive, fast, and completely untrustworthy.
With it, AI becomes a powerful extension of your content operations. Writers remain in control. Documentation stays aligned with the truth. Teams can scale with confidence. 🤠
How to Retroactively Build a Technical Documentation Style Guide Using AI — And Use It to Spot Content Gaps
Technical writers know the pain of “tribal knowledge” all too well. Small teams often share unwritten rules about tone, formatting, terminology, and compliance expectations. Over time, those unwritten norms become invisible — but new writers, contractors, and especially AI tools need those rules documented.
The good news: modern AI systems can help you extract a style guide directly from your existing content and use it to identify what’s missing in your documentation.
In this short from the webinar “Leveling Up: From AI Table Stakes to AI Automation,” host Melanie Denise Davis (“The AI Wrangler”) talks with AI expert and trainer, Bill Raymond, about how teams can retroactively build a usable style guide by leveraging AI. Raymond explains that modern AI tools — such as Microsoft Copilot, ChatGPT, Claude, and Gemini — can connect directly to a team’s existing documentation, analyze patterns, and generate an initial style guide from published content.
He emphasizes that this draft is only a starting point: writers can iterate by correcting tone, removing unintended patterns (like sarcasm), and adding organization-specific rules such as compliance requirements and approved citation sources. Once refined, the guide can be downloaded and used as a formal reference.
Raymond also notes that once AI understands the team’s content and style, it can help identify gaps, compare coverage against competitors, and generate practical roadmaps—such as what to produce in the next two weeks or two months—making AI a powerful partner in turning tribal knowledge into a strategic content advantage
Here’s a short review of some of the advice he shared during the show.

Connect AI to Your Existing Docs
Today’s leading AI tools — such as Microsoft Copilot, ChatGPT, Claude, and Gemini — can all connect to your documentation repositories. Once connected, the model can read your published content and begin to infer the patterns your team follows.
If you’ve never created a formal style guide, you can give the AI a simple instruction:
“Review these documents and create a style guide based on them.”
The model will scan your content and produce an initial draft. It won’t be perfect, but that’s the point — you now have something concrete to refine.

Iterate and Correct the AI’s Draft
AI-generated style guides sometimes surface unexpected rules. If the model finds a sarcastic sentence or two in your archives, it may conclude that sarcasm is part of your brand voice.
With a chatbot, you can interrogate and correct it:
“We don’t use sarcasm. Remove that rule.”
“We are a compliance-oriented organization. Add requirements for legal citations from our approved sources.”
This iterative process lets you shape the AI’s output into an accurate reflection of your team’s expectations. When you’re satisfied, you can export the document as your official corporate style guide.

Use the Style Guide and AI Together to Identify Gaps
Once the AI understands your style, your content, and your rules, you can take the next step: ask it what’s missing.
Because the model now has full visibility into what you’ve published, it can answer questions like:
“What topics are competitors covering that we are not?”
“What gaps exist in our current documentation set?”
With those insights, you can begin structured brainstorming. For example:
“Given a two-month timeline, what can I realistically create?”
“What could I produce in the next two weeks?”
“What should be completed by the end of two months?”
The model will generate a prioritized, reasonable plan based on your resources — whether you’re a team of one or many.

From Tribal Knowledge to Strategic Advantage
AI can help you transform undocumented norms into a structured, maintainable style guide. And once that guide exists, the same AI can surface content gaps, suggest improvements, and help you plan your next steps.
By letting your published work teach the AI what “good” looks like — and then refining it — you turn your accumulated content into a source of clarity, consistency, and strategic insight for your technical writing practice. 🤠
Free Course: Become an Explanation Specialist
We explain things constantly — at work, with friends, and in our closest relationships. Every one of us is an explainer.
But most of the time, our explanations just… happen. We fall back on habits we’ve carried for years. Some people naturally communicate with clarity. Others learned pieces of the skill in school or through experience. Many struggle. And everyone — every single one of us — can get better.
That’s where the Explainer Academy comes in.
In this free course from our friends at CommonCraft, I invite you to take a fresh look at how you communicate. You’ll see that explanation isn’t a fixed trait. It’s a skill you can sharpen. And because we explain things so often, even a small improvement can make a big difference. 🤠
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
A Flight of Static Site Generators: Sampling the Best for Documentation
I’ve been volunteering at our local elementary school in the school library. This week, the creative head librarian held a “book tasting party” where she placed books of different genres at six different tables and had class groups rotate from table to table to “taste” each type of book. From horror to graphic novels, there was a book genre for many tastes.

Photo by Pritesh Sudra on Unsplash
Imagine if you could have a “flight” of docs sites to have a docs site tasting party! The docs aficionado in me wants to go to such a party. What would be served? How about a taste of Sphinx, Astro, Hugo, and Jekyll, with a final taste of Mkdocs and Docusaurus? Let’s have fun with it (even if the metaphor breaks down quickly).
Sphinx: The Rich Espresso for Documentation 
Sphinx is a powerful documentation generator initially created for Python projects. It excels at producing structured, text-heavy documentation emphasizing cross-referencing and indexing. Using reStructuredText as its markup language, Sphinx offers robust extensibility through various plugins and themes. Many technical documentation teams appreciate its ability to generate outputs in multiple formats, including HTML and PDF. However, its complexity can be daunting for newcomers unfamiliar with its syntax or configuration.
Astro: The Sparkling Citrus Spritz of Static Sites 
Astro is a modern static site generator designed for speed and flexibility. Unlike traditional SSGs, Astro allows developers to mix and match different frontend frameworks like React, Vue, and Svelte while focusing on shipping minimal JavaScript to the browser. This approach makes Astro an excellent choice for performance-conscious documentation sites. With its component-driven architecture, Astro enables content creators to build engaging doc experiences while maintaining simplicity in content management.
Hugo: The Smooth Bourbon of Speedy Site Generation 
Hugo is one of the fastest static site generators available, and it is known for its speed and efficiency. Written in Go, Hugo boasts nearly instant build times, making it a favorite among developers who need quick iterations. It uses Markdown for content and has a powerful and flexible templating system. Hugo is ideal for large-scale documentation sites, thanks to its excellent support for taxonomies, multilingual content, and customizable themes. However, the learning curve can be steep for those unfamiliar with its templating language.
Jekyll: The Classic Red Wine of Static Sites 
Jekyll is a well-established static site generator that powers GitHub Pages, making it a popular choice for open-source projects. Built with Ruby, Jekyll processes Markdown files and converts them into static HTML. Its simplicity and deep integration with GitHub make it an appealing option for developers looking for an easy way to deploy documentation. While Jekyll offers plugins and themes, its speed and flexibility may not match newer SSGs like Hugo or Astro. Still, it remains a reliable choice for lightweight and version-controlled docs sites.
MkDocs: The Refreshing Iced Tea of Documentation
MkDocs is a straightforward static site generator designed explicitly for documentation projects. It prioritizes ease of use with a simple configuration file and Markdown-based content. MkDocs includes a built-in live preview server, making it easy to see changes as you write. One of its most popular themes, Material for MkDocs, enhances the experience with modern styling and extra features. While MkDocs may not be as extensible as Sphinx, it is an excellent choice for teams looking for a quick, efficient way to publish documentation.
Docusaurus: The Trendy Matcha Latte of Docs 
Docusaurus, developed by Facebook, is a React-based static site generator optimized for documentation sites. It provides out-of-the-box support for versioning, internationalization, and a structured navigation system. Docusaurus embraces a modern development approach, allowing developers to leverage React components for interactive documentation. Its ecosystem includes a vibrant community and a growing number of plugins. While its reliance on JavaScript may be a drawback for those seeking pure static solutions, Docusaurus remains a top contender for teams wanting a dynamic, developer-friendly documentation site.
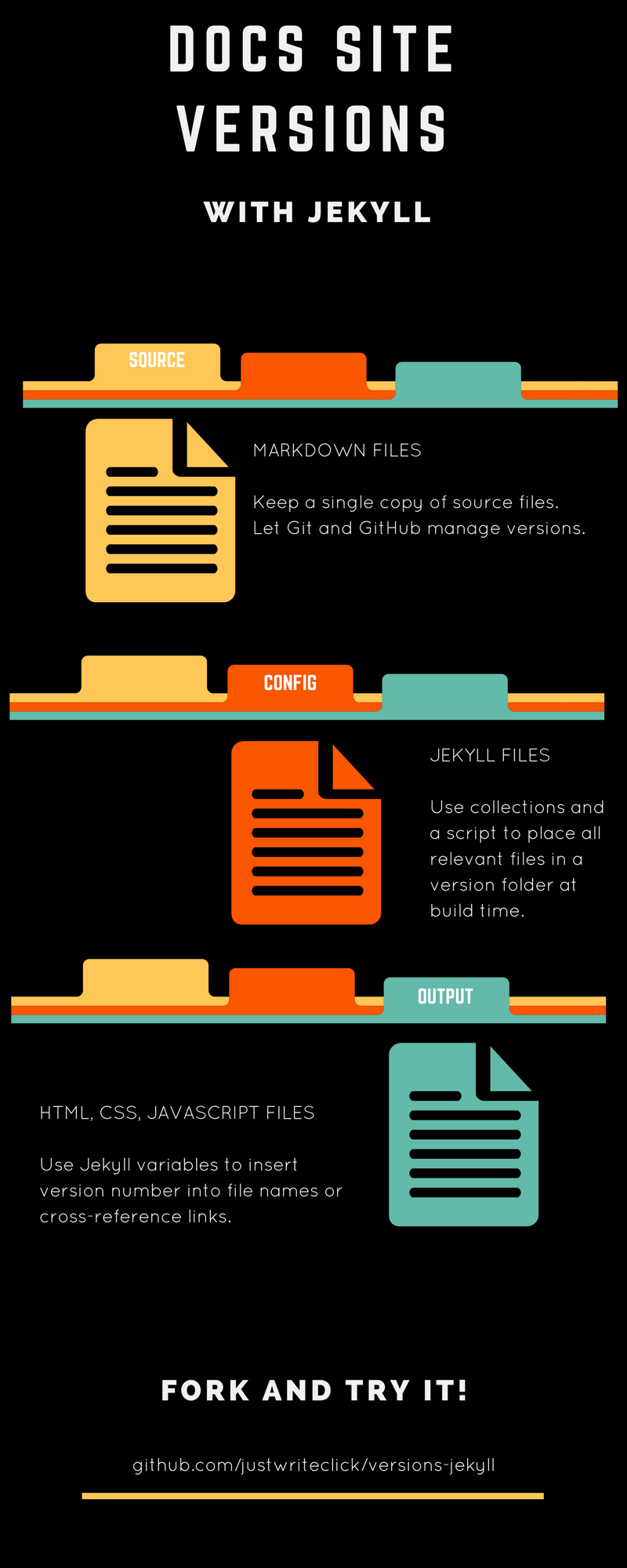
The post A Flight of Static Site Generators: Sampling the Best for Documentation first appeared on Just Write Click.Every DITA topic should be able to fit anywhere. (Not really.)
When I talk to writers about this, I state the case strongly: every topic should be able to fit anywhere. That always provokes some pushback, which is good. Of course it’s not really so, in practice. There are many combinations of topics that are just never going to happen. However, on a large scale, with hundreds or thousands of topics, there are many, many plausible combinations, some of them completely unexpected.
In fact, there are so many plausible combinations, you might as well not worry about the impossible ones. You might as well just go ahead and write each topic as if you had no idea what parent topic it was going to be pulled into.
That’s what we mean by “unleashing” your content with DITA. It’s the combinations of topics that bring the value, not the individual topics themselves. If you draft each individual topic so that it’s eligible for the largest possible number of combinations, you’ve multiplied the usefulness to the user (yes, and the ROI, and the technical efficiency) of the information in that topic. For any given topic, it’s true, there may be only three or four conceivable combinations in which it could make sense. For some, there might be hundreds. You’re not going to know unless you write for reuse in every case.
Once we’ve put this into action, we can go back to the managers and gurus and say, now you’ve really got ROI; now you’ve really got efficiency. Because we’ve given you something that is worth investing in, something that’s worth producing efficiently. Something that can delight readers with its usefulness and its elegance. This isn’t just content, this is writing.
DITA makes it possible for any information set, no matter how complex and huge, to be represented with a single page.
In any information set, every component should be able to roll up into what is ultimately a single top-level summary. We know most readers don’t come in through the front door, but in principle you can provide the reader with an entry point that fully sums up what’s in the information set. From there they can drill down into more and more detailed levels. (Readers can be very easily trained to do this, because they have learned from their previous reading to scan for summary-like information and use that to judge whether it’s worth reading on for more detail.)
If each level is itself a rolled-up collection of subordinate units, and so on in turn down the ranks, what you are offering is a set of pages in which each page is itself a table of contents. The content is the navigation and the navigation is the content.
Picture this single page sitting at the apex of a pyramid. It contains (describes) everything that is included in that pyramid. Not that many people are ever going to actually read that page, but we need it to be there, because it defines the pyramid.
The bigger the pyramid, the higher level the information in its top node is going to be. So, for a very large information set, that single page is going to be very general. Each of its immediate child pages will be a level more detailed, and each successive level is going to be more detailed, until you get to the bottom “leaf” level where a topic describes only itself.
Modularity is what makes it fun to write with DITA.
The most disorienting thing about learning structured writing is modularity. There are a lot of things we’ve learned about writing that we have to unlearn; this is the most fundamental of them. This is way bigger than deciding it’s OK to dangle a preposition.
Modularity means, in practice, conveying meaning in free-standing chunks instead of in a unified stream. Why is it so great to be free-standing? What does that get me, from a purely authoring perspective? (Remember, we’re still excluding managerial and technical perspectives from this conversation. You folks can come on back later.)
In mature DITA writing, many topics are built up automatically from component topics. Done well, these composite topics look like you lovingly handcrafted them with sections, section titles, section detail, overview material, and so on. In fact, you threw them together on the fly from component topics that you happened to have lying around.
How good your built-up topics are depends on how good those component topics are. How good the components are is largely a function of how well each one delivers meaning on its own, without having to wait for any other component to its job.
A composite topic that looks and reads like a composite topic is a failed composite topic. It needs to look and read like it was specifically conceived for this particular user at this particular moment. We want its component topics to match, in tone and style and scope, so well that they look like they were all written at once for this specific collection.
You’re working on a building, from the roof down and from the foundation up at the same time. You know what you need your built-up composite topic to do, which influences how to you’ll define and select or draft its component topics. At the same time, as your component topics come into being, they’ll influence the scope, scale and ultimately the effectiveness of the composite topic you’re building from them. In my experience, it’s when this process gets rolling that you really start to feel like you’re doing interesting, useful writing. This is where the fun starts.
Why is it that good writing feels like speech, but writing that’s transcribed from speech is usually bad writing?
I’m reprising something I put up on this site about five years ago (lightly edited), because it still comes up in conversation occasionally and it’s fun stuff to talk about. Goes a little bit like this:
Writing has a tense, complicated relationship with speech. Good writing gives the illusion of resembling speech, or being derived from speech. But writing that is transcribed from speech is generally bad writing. It doesn’t feel like real speech. Some writing that does feel like real speech seems stilted when you read it out loud. The speech that writing evokes is imaginary speech, speech that takes place in your mind’s ear.
Often someone says something in a meeting that captures a thought perfectly. It may even seem elegant, like something that everyone knows but that hasn’t been expressed so well until now. Someone will say, “Get that down.” Later, at editing time, it turns out to make no sense at all. The context has changed, of course: what’s said in a meeting grows out of the experiences of everyone there, complete with unspoken assumptions, agreements and compromises. Text has little or no context. It appears out of nowhere, bearing all of its antecedents within itself. It has no hope of matching the immediacy of a spoken conversation. But we can rely on it to a degree that we can’t rely on our memory of speech.
DITA can transform our writing, but only if we take control of it as writers.
Let’s leave aside, for now, the whole technical thing. Let’s separate creating content from building deliverables, at least abstractly. Let’s just talk about how we can use DITA to create beautiful, thrilling texts.
The first thing to acknowledge is that DITA is not just an XML-based way of producing the same kinds of products we used to push out with Framemaker. (That would be DocBook.) DITA is so much more than that. It’s a new way of writing. It invites us to look at our writing in a completely different way.
When people talk about DITA they almost always talk from one of two overlapping perspectives: the technical guru or the publication manager. Writers have reason to care about some of the same things those two care about, but neither focuses on what really matters to tech writers.
-
To the technician, DITA is mainly about all the awesomely efficient processing and automation you can do. To a writer, efficiency is great as a means to get good writing in front of readers. It’s not an end in itself.
-
What sells DITA to a manager is the cost savings from reuse and processing efficiency. Writers care about saving money too — to hire more writers with, of course — but investment only matters to us if it’s in pursuit of better content.
I suspect that’s why there are a lot of DITA-based help sites out there that aren’t really much better than the old paper or PDF or Winhelp or Dreamweaver products that they replaced. Gurus and managers have reconfigured their thinking, but writers haven’t. We’re still trying to write the kind of stuff we grew up writing, and trying to jam it into a new kind of container. But this new container demands a new kind of content.
The mobile future of content
The publisher's gold mine
Fully mobilizing rich media through content management
Search
Recent Content
- Forum for DITA Users
1 year ago - Publishing for DITA
6 years ago - Optimizing the DITA Authoring Experience — Online Course
6 years ago - Linking to another chunked topic
6 years ago - Advanced Reuse Strategies — Online Course
6 years ago - 2019 Content Management Strategies/DITA North America Conference
7 years ago





{kind=link}
{kind=link}