DITA
What is a Chief Information Officer?
The Chief Information Officer (CIO) is the adult in the room who is responsible for everything that plugs in, connects to Wi-Fi, stores, moves, secures, or even breathes near company information.
If a system crashes, a server overheats, or someone clicks on an email promising a free vacation to a romantic paradise, the CIO’s blood pressure rises in direct proportion.
In theory, the CIO sets enterprise technology strategy. In practice, they referee a daily cage match between innovation and risk.
The Chief Executive Officer (CEO) wants AI everywhere. The Chief Financial Officer (CFO) wants to lower cost. The Chief Information Security Officer (CISO) wants nothing to move ever again. The marketing team wants a new platform by Tuesday. The software engineers want six months and a clean rewrite of the code. The CIO wants a nap.

CIOs live in a world of acronyms that sound like secret codes: ERP, CRM, IAM, SIEM, SASE. They speak fluent “roadmap” and can say “governance framework” without blinking. They must believe in transformation while also working non-stop to prevent catastrophe, which is a bit like remodeling your kitchen during a hurricane.
A good CIO sees around corners. A tired CIO sees around corners and finds another compliance audit waiting there. They are tasked with modernizing legacy systems built in the late Cretaceous period while keeping the company running 24/7, because downtime is apparently more offensive than sin.
They are equal parts strategist, diplomat, therapist, and fire marshal. They promise agility while enforcing controls. They encourage experimentation but quietly calculate the blast radius of every experiment. They know that “just one small integration” is rarely small and never — ever — just one.
If everything works, no one notices. If one thing breaks, everyone notices.
Which means the CIO’s true job description might read: Keep the lights on. Keep the hackers out. Make it scalable. Make it cheaper. Make it faster. And whatever you do, don’t let it be your fault. 🤠
Krisp launches real-time Voice Translation SDK
Dataiku launches 575 Lab, its new open source initiative for responsible AI
Graphwise announced the immediate availability of GraphRAG
300-node clusters now supported in CockroachDB
LLMs vs. LRMs: What’s the Difference and Why It Matters to Tech Writers
What is an LLM (Large Language Model)?
An LLM predicts the next most likely token based on patterns learned from massive amounts of text.
What it’s good at:
Fluent language generation
Summarizing, rewriting, translating
Answering questions that resemble things it has seen before
What it is not designed to do:
Prove correctness
Track rules or constraints reliably
Reason step-by-step unless prompted very carefully
Key limitation for technical documentation:
An LLM can sound right while being wrong — confidently.
This is one reason why LLM-only chatbots hallucinate procedures, mix product versions, and invent configuration options.
What is an LRM (Large Reasoning Model)?
An LRM is designed to reason, not just predict text. It explicitly performs intermediate steps such as planning, verification, constraint checking, and logical evaluation before producing an answer.
Common characteristics:
Multi-step reasoning
Internal validation of outputs
Better handling of math, logic, and procedures
More deliberate (and often slower) responses
Think of it this way:
LLM: “What sounds like the right answer?”
LRM: “What must be true for this answer to be correct?”
A current example category includes “reasoning models” like OpenAI’s o-series (for example, o1), though the industry is still settling on standard terminology.
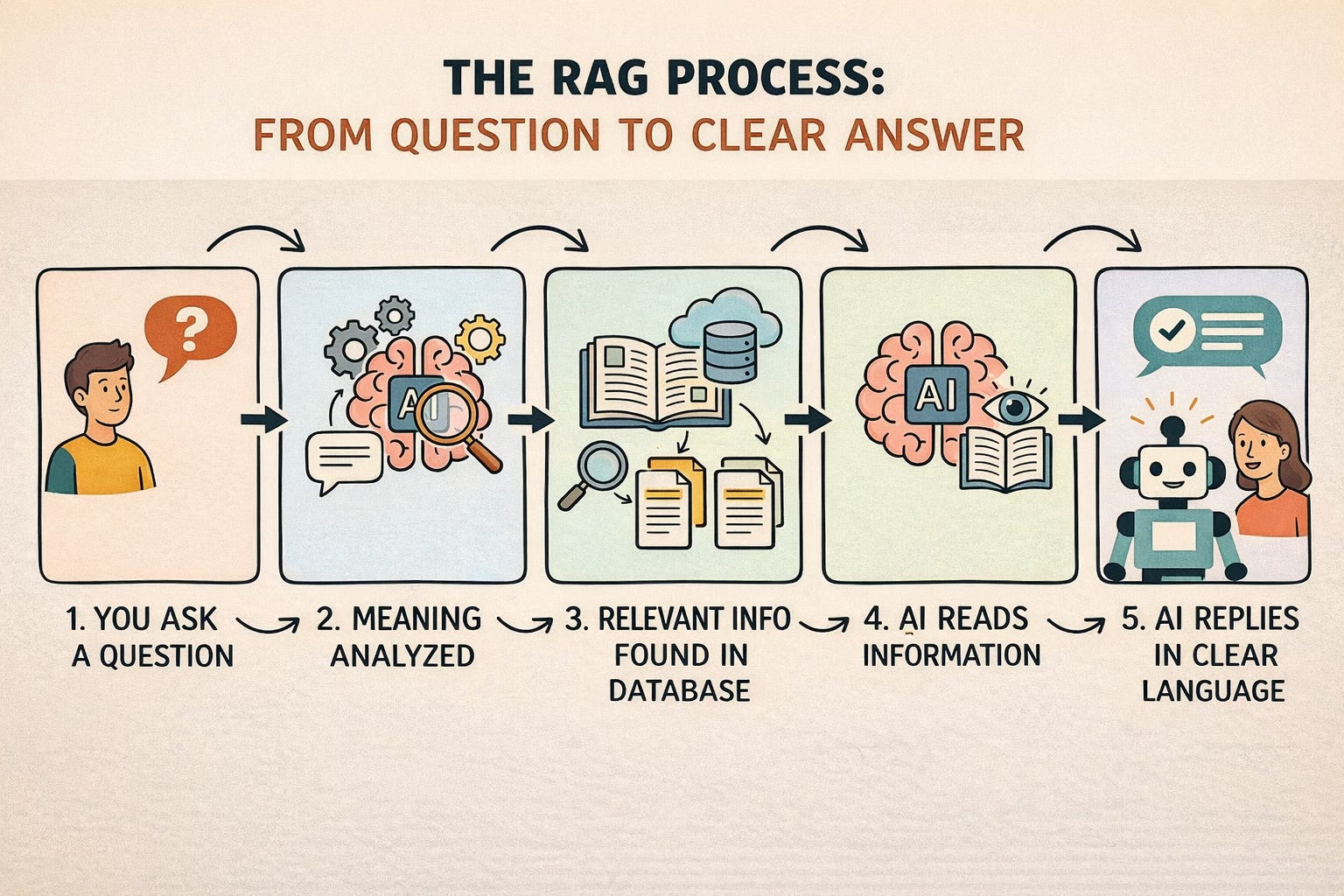
Why Tech Writers Should Care (A Lot)
For a long time, documentation had a fairly predictable role. People searched it, skimmed it, and read it. If they misunderstood something, that misunderstanding usually stayed local. The consequences were real, but they were bounded by human interpretation.
That boundary no longer exists.
Today, AI systems sit between your documentation and your users. They answer questions, explain features, recommend actions, and onboard customers. Increasingly, they do not simply quote documentation. They reason over it. That shift fundamentally changes the stakes.
With traditional LLMs, poor documentation produced awkward or incorrect answers. With reasoning-oriented models, poor documentation produces incorrect decisions. A vague prerequisite, an implied condition, or an ambiguous rule is no longer just a writing issue — it becomes a logical flaw that propagates through automated systems. When an AI reasons from content that is incomplete or inconsistent, it fills in the gaps with confidence.
This is where the difference between “sounds right” and “is right” becomes painful.
As LRMs come into play, documentation stops behaving like narrative text and starts functioning like a knowledge system. Models attempt to infer intent, reconcile contradictions, and determine applicability. If your content relies on human intuition — phrases like “usually,” “in most cases,” or “as needed” — the model has nothing solid to anchor to. Humans fill those gaps naturally. Machines guess.
That guessing erodes trust. And trust is now part of the product.
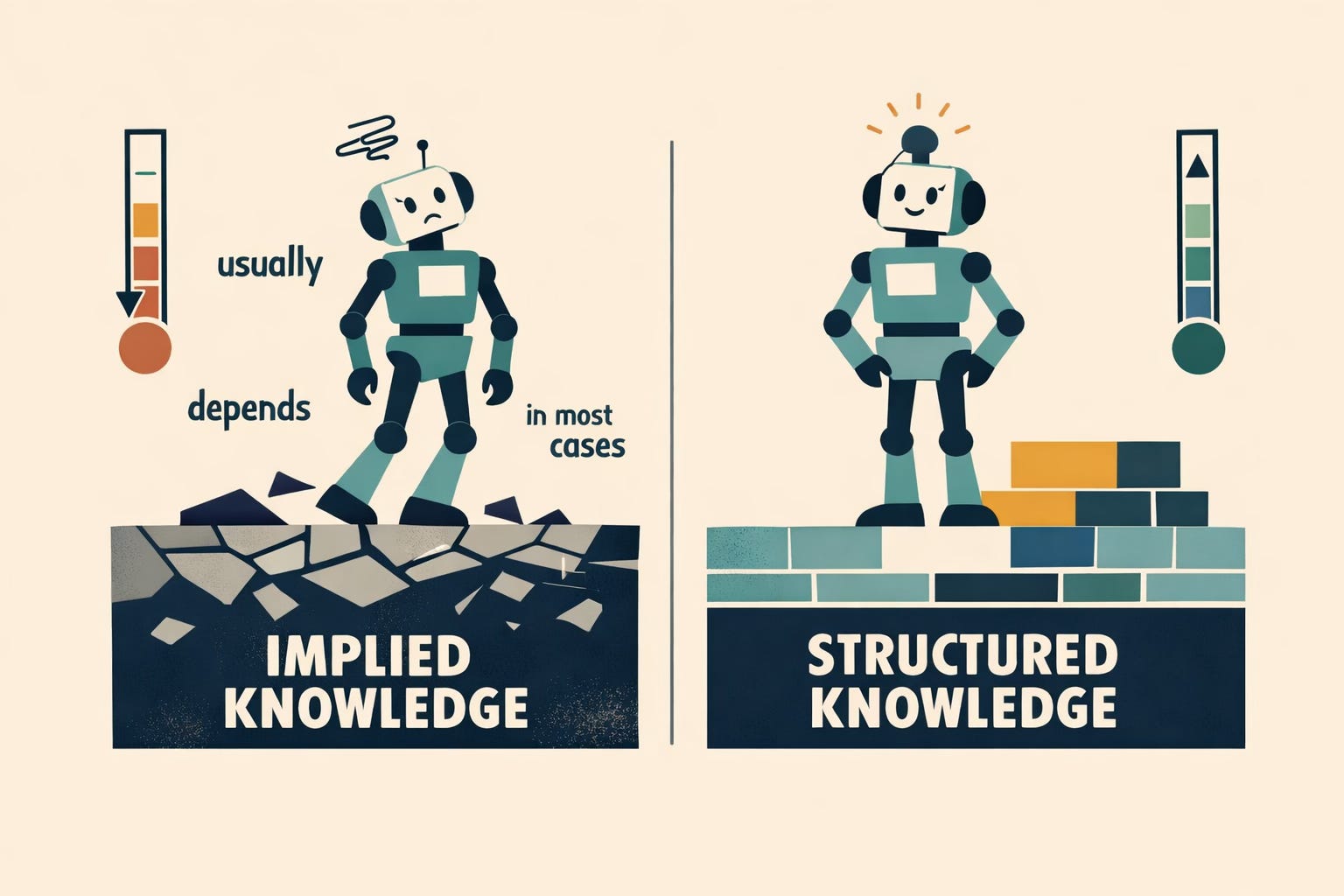
This also reframes what “AI-ready documentation” really means. Early conversations focused on whether chatbots could answer questions from docs. The more important question now is whether AI can reason correctly from those docs. That depends far less on elegant prose and far more on structure, clarity, and intent. Modular topics, explicit conditions, clean version boundaries, and clearly stated rules outperform beautifully written but loosely organized pages.
For tech writers, this is not a threat. It is a return to relevance.
As organizations realize that AI output is only as reliable as the knowledge beneath it, someone must own that knowledge. Someone must decide what is authoritative, what applies in which context, and what must never be inferred. That work does not belong to the model. It belongs to the people who design, govern, and maintain the content — tech writers.
In a reasoning-driven world, documentation is no longer passive reference material. It is operational input. It drives automated explanations, customer decisions, and support outcomes. When something goes wrong, leaders will not ask, “Why did the AI hallucinate?” They will ask, “Why did our knowledge allow it to?”
Tech writers are uniquely positioned to answer that question — and to prevent it from being asked at all.
The Practical Takeaway For Tech Writers
You do not need to become an AI engineer. You do need to write content that survives reasoning, not just reading.
That means:
Making assumptions explicit
Separating rules from examples
Removing ambiguity and implied steps
Enforcing version and product boundaries
Treating documentation as executable knowledge
👉🏾 LLMs reward good writing. LRMs reward good information architecture. 🤠
See also:
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Gilbane Advisor 2-11-26 — multi-agent architectures, SaaS & CaaS
When AI Gets Smarter Than Your Content: Why the Kinetic Council Arrived Right on Time
By Scott Abel, The Content Wrangler
If you’ve spent the last two years working to convince executives that generative artificial intelligence (genAI) is not a magical oracle that can decode your company’s content chaos into helpful customer experiences, congratulations — you’ve already glimpsed the future that the newly formed Kinetic Council is preparing us for.
Of course, artificial intelligence (AI) isn’t the problem. The problem is that we’re feeding AI systems content the way a toddler feeds a DVD player — shoving in whatever fits and hoping something delightful happens.
Instead, we get mishaps, hallucinations, compliance failures, broken customer journeys, and outputs that read like the chatbot is having an existential crisis.
AI augmentation (think adding semantic metadata) and structural transformation aren’t “nice to have” any longer. They are the cost of entry for intelligent experiences.
And the savvy pros who know how to build this foundation — content strategists, technical writers, data modelers, taxonomists, ontologists — are suddenly more essential than ever. So essential, in fact, that they just got a new professional home.
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.

Enter the Kinetic Council, a freshly minted 501(c)(3) nonprofit built for this moment of upheaval, transformation, and (dare we say) opportunity. Think of it as the guild for the era of intelligent systems. A place where the people who design, structure, model, and operationalize knowledge can build the future together instead of quietly fixing everyone else’s messes from the shadows.
A Professional Landscape in Freefall
The Kinetic Council didn’t appear because someone thought, “What the world really needs is another association.” It appeared because the institutions that once served knowledge professionals collapsed. The Society for Technical Communication (STC) — a foundational organization for more than 70 years — shut down. The Special Libraries Association also shuttered. Two pillars of the knowledge industry vanished just as AI reshaped everything about how knowledge distribution works.
As Cruce Saunders, the Council’s founder and chair, says, “The death of STC isn’t just an ending. It’s a signal that we’re ready for something new.”
For decades, content creators, data architects, and semantic specialists were treated like separate species who occasionally shared a conference hallway but rarely a strategic conversation. AI shattered that illusion.
Today, every functioning intelligent system depends on the convergence of these domains. Content professionals shape what humans need. Data professionals shape how information flows. Semantic professionals shape how concepts relate and how systems reason.
These worlds are no longer adjacent. They are — as Peter Morville of Semantic Studios declares — intertwingled.
We Need “Kinetic” Content Because Static Knowledge Doesn’t Power AI
The Council’s name reflects a foundational shift. Nothing is static anymore (not content, not data, not user intent, and certainly not the systems delivering knowledge). We’ve moved from publishing to orchestrating. From structured documents to continuously adapting knowledge flows. From managing information to engineering the substrate that AI relies upon to behave responsibly.
The Council expresses this as a “golden thread”: Human structured content → semantically enriched → powering intelligent AI systems
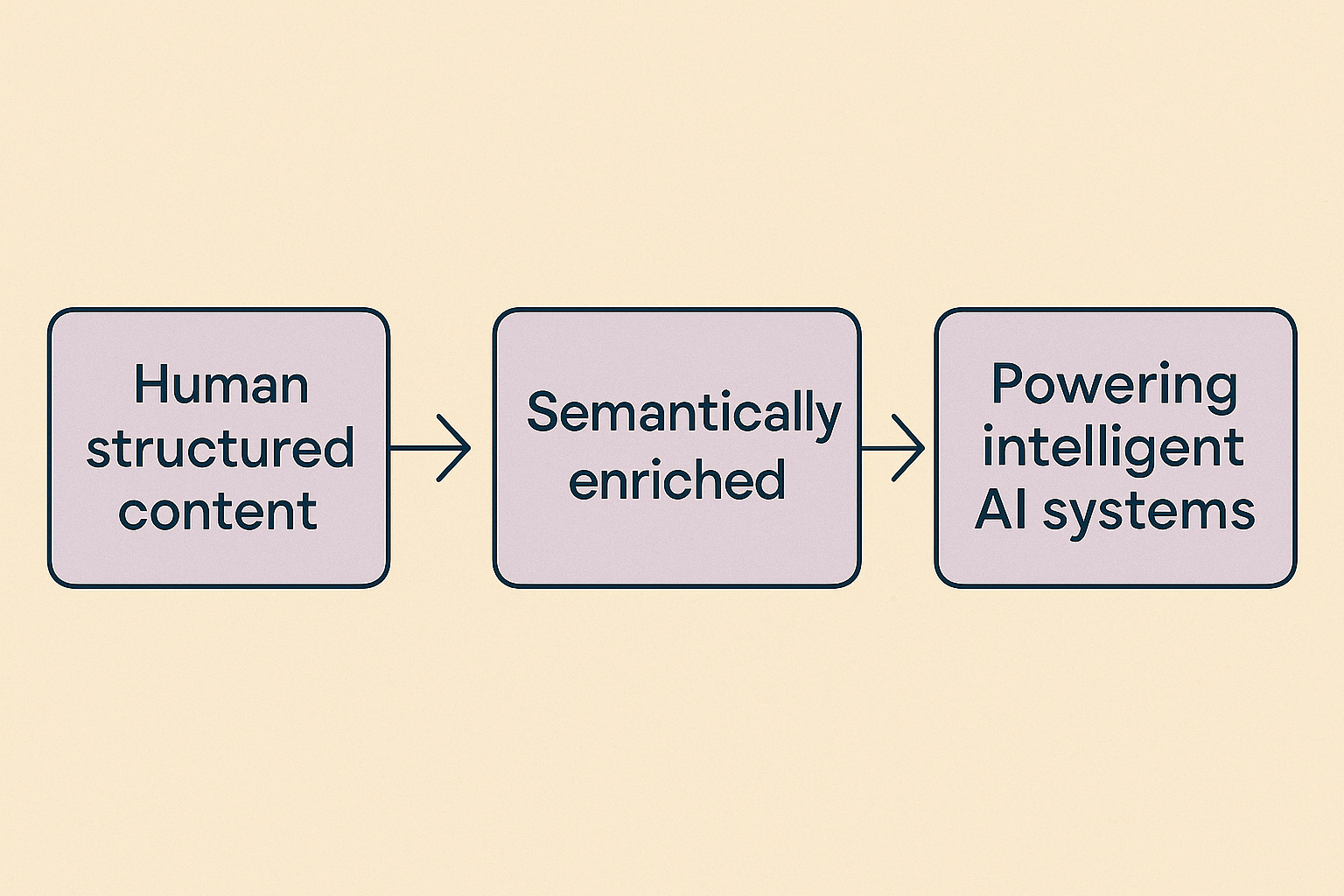
This isn’t poetry. It’s the architectural reality behind every AI system that actually works.
Why This Organization Is Needed Now
Three forces collided that made the Kinetic Council not just useful, but necessary.
1️⃣ The first is AI anxiety — a workplace epidemic that has left many professionals wondering whether automation will erase entire career paths. Despite the bold claims circulating in Silicon Valley, the idea that AI can replace the people who build, manage, and maintain the knowledge layer is fantasy.
AI is only as reliable as the structure and semantics that guide it. Without them, organizations simply scale risk faster.
2️⃣ The second is an enormous skills gap. Traditional educational pathways don’t prepare professionals to design knowledge graphs, orchestrate multi-agent workflows, or establish the governance frameworks needed to prevent AI systems from drifting into nonsense.
Most organizations don’t even know how to hire for these capabilities yet.
3️⃣T he third is the collapse of professional infrastructure. With STC gone, thousands of practitioners needed a place to gather, learn, collaborate, and evolve. The Kinetic Council stepped into that vacuum.
What the Kinetic Council Actually Is
The Council brings together professionals across content, data, and semantics — recognizing that these are no longer discrete career tracks but interdependent components of a single field. Its leadership includes long-standing figures in content, strategy, and semantic design: Deane Barker as president, Cruce Saunders as founder and chair, Hilary Marsh as secretary, Rahel Bailie guiding communications, and Larry Swanson shaping semantic and ontology frameworks.
It is, in effect, a professional big tent for those who architect knowledge systems.
A Certification for the Intelligent Era
One of the Council’s most significant contributions is the upcoming Knowledge Architecture Professional certification (launching in 2026 with Virginia Tech). It is intended for practitioners who already know how to structure content or model data and want to understand how those skills translate into AI-enabled knowledge systems.
The program introduces kinetic information concepts, schema and content model development, semantic layering, taxonomy and ontology work, and foundational knowledge graph design. A capstone integrates these components into a real-world challenge.
If you have ever found yourself explaining to a colleague that the reason a chatbot is hallucinating is because the system doesn’t understand the distinction between a concept, a component, and a configuration setting, you are already qualified for this curriculum.
Why CX, EX, DX, and Marketing Leaders Should Care
Leaders should care because customer experience is now mediated by AI in more ways than most organizations acknowledge. And AI, despite its fluency, is brittle. It depends not on clever prompts or model size but on well-structured, semantically rich, well-governed knowledge.
This is why the Kinetic Council’s mission matters so deeply to leaders in digital experience and customer experience. AI will not save you from your content debt. It will shine a spotlight on it. The foundation for trustworthy AI isn’t the model — it’s the knowledge architecture behind it.
Companies deploying AI without a semantic spine are discovering that you can scale hallucinations far more quickly than you can scale accuracy. The only safeguard is the people who understand structure, intent, governance, and meaning.
And those people now have a professional home.
The Future Role of Content Professionals
The Council isn’t preserving past identities. It’s articulating future ones.
Technical communicators and content strategists are no longer only creating content. They are designing the systems through which content becomes knowledge and knowledge becomes action. They are moving from producing artifacts to orchestrating ecosystems. From writing documents to mapping the logic that determines how AI decides what to generate, when to generate it, and why.
Saunders puts it this way: “We are not being displaced by AI. We are being called to guide AI toward serving human flourishing.”
That shift is already underway in organizations everywhere. The Council simply names it, formalizes it, and supports the people living it.
How To Participate
If you work in digital experience, customer experience, content design, or marketing, the shifts the Council is responding to are already shaping your work. Your systems are getting smarter (on good days) and more unpredictable (on most days). Your teams are hungry for clarity and guidance. And your content and data foundations are under unprecedented strain.
You can participate in several ways. You can join the Council’s community, contribute your own expertise, and collaborate with others who are defining best practices for AI-era knowledge work. You can explore the educational programs, mentor emerging practitioners, or advocate in your organization for the structural investments your AI initiatives truly require.
What matters most is taking part in shaping the profession that will define the next decade. The silos that dominated this landscape for 20 years are gone. A new, integrated field is emerging. And the Kinetic Council is the first organization building the infrastructure for it.
Be Part of Architecting What’s Next
AI is rewriting the landscape of digital experience, but it isn’t rewriting the laws of knowledge. Organizations that place structured content, semantic clarity, and knowledge architecture at the center of their AI strategies will define the next era of trustworthy, human-centered intelligent systems.
The Kinetic Council didn’t arise to preserve what was lost. It arose to architect what comes next.
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
What Is Ontology-Grounded Retrieval-Augmented Generation?
Technical writers keep hearing that Retrieval-Augmented Generation (RAG) makes AI answers more accurate because it grounds responses in real content. That is true — but it’s only part of the story.
RAG is often described as “LLMs plus search.” That description is incomplete — and for technical writers, potentially misleading.
Ontology-grounded RAG is a more advanced approach that anchors AI responses not just in retrieved content, but in an explicit semantic model of meaning. It ensures that AI systems retrieve and generate answers based on what things are, how they relate, and under what conditions information is valid.
If AI is becoming the public voice of our products, ontology-grounded RAG is how we keep that voice accurate, consistent, and accountable.
If you work with structured content, metadata, or controlled vocabularies, this topic is very much in your lane.
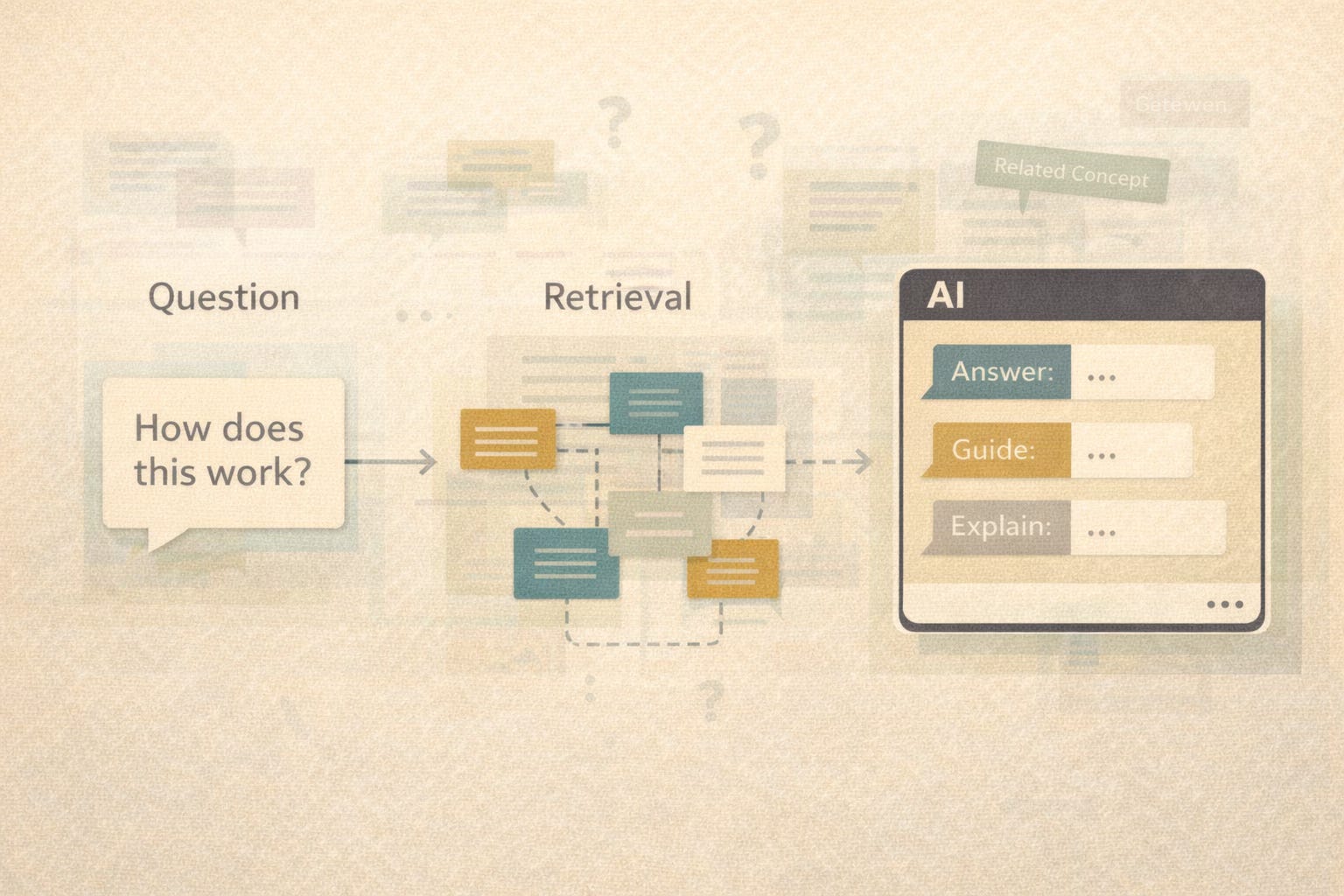
Why Standard RAG Is Insufficient
Standard RAG works like this:
A user asks a question
The system retrieves relevant chunks of content (documents, passages, topics)
An LLM generates an answer using that retrieved text as context
This improves accuracy over “pure” generative AI, but it still has limits:
Retrieval is often keyword- or embedding-based, not meaning-based
Related concepts may not be retrieved if the wording differs
The model may mix incompatible concepts or versions
There is little accountability for why something was retrieved
What Changes With Ontology-Grounded RAG?
Ontology-grounded RAG adds a formal knowledge model — an ontology — between your content and the AI.
An ontology explicitly defines:
Concepts (products, features, tasks, warnings, roles, versions)
Relationships (depends on, replaces, applies to, incompatible with)
Constraints (this feature only applies to this product line or version)
Synonyms and preferred terminology
Instead of asking, “Which chunks are similar to this question?” the system can ask:
“Which concepts are relevant, and what content is authoritative for those concepts in this context?”
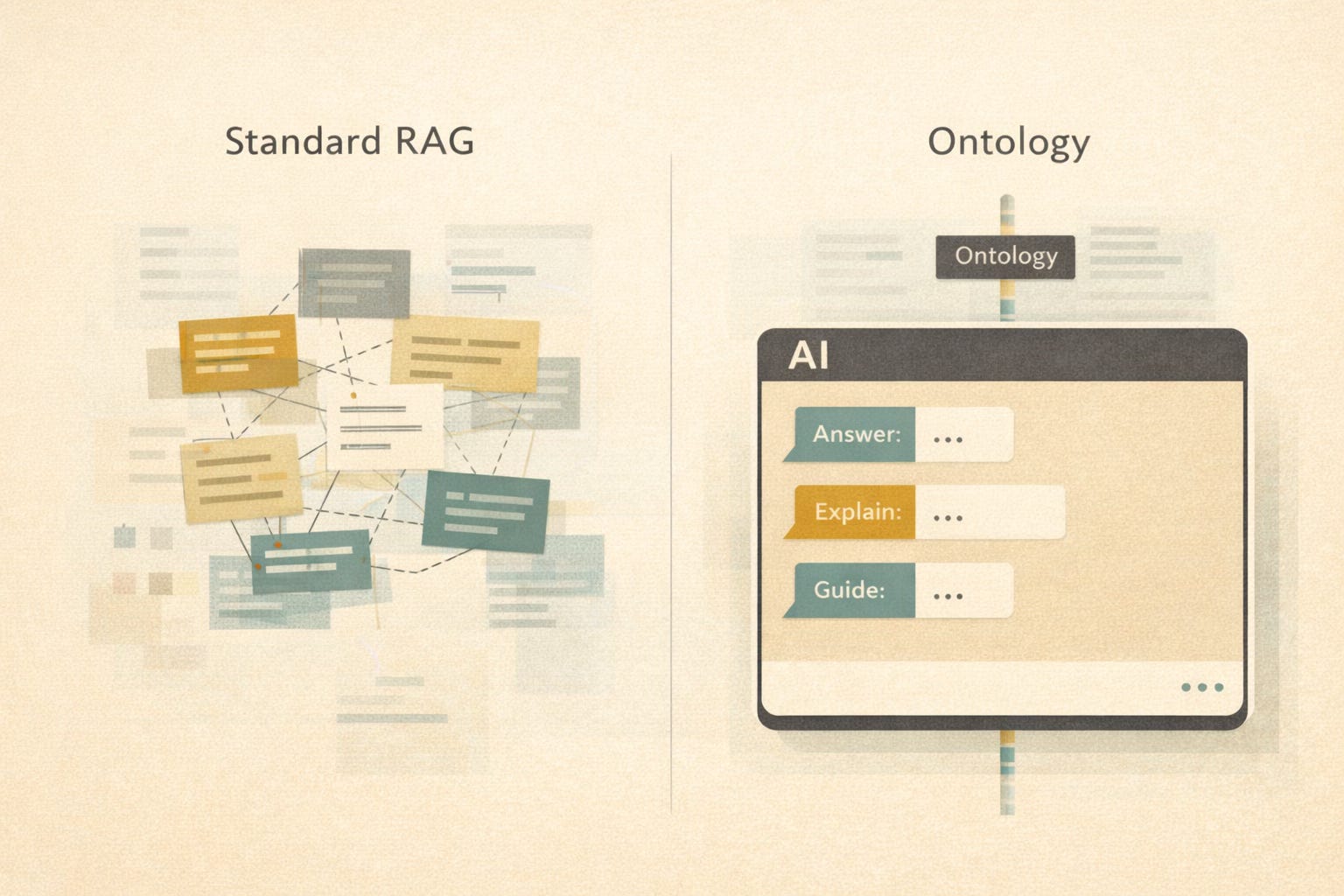
Ontology-Grounded RAG In Plain Language
Here is the simplest way to think about it:
Standard RAG retrieves text that looks relevant
Ontology-grounded RAG retrieves content that means the right thing
The ontology acts as a semantic spine that keeps AI answers aligned with reality.
Why technical writers should care
Ontology-grounded RAG rewards practices technical writers already value:
1. Clear concept definitions
If we cannot clearly define what a “feature,” “module,” or “service” is, our AI cannot either.
👉🏾 Ontologies force clarity.
2. Structured, modular content
Topic-based authoring (DITA, component content) maps naturally to ontological concepts.
👉🏾 Long narrative documents do not.
See also: What is the Darwin Information Typing Architecture (DITA)?
3. Metadata that actually matters
In ontology-grounded systems, metadata is not decorative. It drives:
Retrieval
Filtering
Disambiguation
Answer justification
👉🏾 This turns metadata work into high-leverage labor.
4. Fewer hallucinations, better trust
When an ontology enforces relationships and constraints, the AI cannot easily:
Combine incompatible product features
Ignore version boundaries
Answer outside its authority scope
👉🏾 This is how you move from plausible answers to defensible answers.
How Technical Writers Can Make AI Systems That Use Product Documentation Trustworthy
AI systems now answer customer questions, explain features, and guide users of an increasing variety of products and services through tasks they need to complete.
In many organizations, they do this instead of sending people to the documentation.
Sometimes they do it without ever showing the customer the documentation at all.

This means our technical documentation has quietly stopped being reading material and started a new career as knowledge infrastructure. It is now the raw material from which AI systems assemble confident, well-phrased answers — whether those answers are spot-on or otherwise wildly incorrect.
Recent research (👈🏽 PDF) from EMNLP 2025 Conference on Empirical Methods in Natural Language Processing explains why so many of these systems sound smart while being wrong, and why fixing the problem has less to do with “better AI” and more to do with how documentation is structured.
Let’s talk about what the research found (and why tech writers are holding the keys to AI success, whether they asked for them or not).

First, Let’s Be Very Clear About What This Is Not
This is not about documentation of AI products.
This is about AI systems that:
What Are Ontologies?
In the documentation field, technical communicators often use words like taxonomy, metadata, controlled vocabulary, and knowledge graph interchangeably. They are not the same thing.
An ontology sits above all of them.
If AI systems are now reading, interpreting, and speaking on behalf of our documentation, understanding what an ontology is—and what it is not—becomes essential.
A Plain-Language Definition of Ontology
In the context of technical documentation:
An ontology is a formal model that defines what things exist in our domain, what they mean, and how they are allowed to relate to one another.
It does not store content. It does not store prose. It defines meaning and rules.
Why “Meaning” Matters More Than Ever
Traditional doc systems assume a human reader. Humans infer meaning from context, tolerate inconsistency, and notice when something feels “off”.
AI systems do none of that reliably. They need meaning to be explicit, not implied; exactly what an ontology provides.
What An Ontology Actually Contains
In technical documentation, an ontology typically defines four things.
1. Concepts
The things that exist in your product and documentation universe.
Examples:
Product
Product version
Feature
Component
Task
Configuration
Warning
Error message
API endpoint
User role
An ontology answers: “What kinds of things are we allowed to talk about?”
2. Relationships
How those concepts connect to each other.
Examples:
Feature is part of Product
Task configures Feature
Warning applies to Task
Feature is deprecated in Version
An ontology answers: “How are these things allowed to relate?”
3. Constraints
Rules that prevent invalid combinations.
Examples:
This feature only applies to certain product versions
This task is only valid for admin users
This configuration is incompatible with another feature
This warning must appear whenever a specific condition exists
An ontology answers: “What must never be combined or inferred incorrectly?”
4. Terminology control
Shared understanding of language.
Examples:
Preferred terms vs. synonyms
Deprecated terms
Acronyms and expansions
An ontology answers: “When we say a word, what do we mean—and what do we not mean?”
Ontology vs. Taxonomy vs. Metadata
These are related, but not interchangeable.
Taxonomy
A taxonomy organizes things into hierarchies.
Example:
Product
Feature
Sub-feature
Taxonomies answer: “How do we group things?”
Metadata
Metadata describes individual content objects.
Example:
Product = X
Version = 4.2
Audience = Admin
Metadata answers: “What attributes does this piece of content have?”
Ontology
An ontology defines the rules behind both.
It answers:
What counts as a Product?
What is the difference between a Feature and a Configuration?
Can a Task apply to multiple Products?
When is something invalid, deprecated, or incompatible?
Without an ontology:
Taxonomies drift
Metadata becomes inconsistent
AI systems guess
Why Ontologies Matter Specifically For Technical Documentation
1. They prevent concept drift
Over time, teams start using the same word to mean different things.
Ontologies force alignment:
A feature is not a task
A task is not a concept
A version boundary is real, not optional
This clarity improves both human comprehension and AI accuracy.
2. They enable trustworthy AI answers
AI systems that rely on documentation increasingly use semantic retrieval and generation.
Without an ontology:
AI retrieves text that sounds relevant
Answers may combine incompatible concepts
With an ontology:
AI retrieves content that is conceptually valid
Constraints prevent nonsense answers
This is the foundation of ontology-grounded RAG.
3. They elevate the role of technical writers
Ontologies surface a truth many organizations ignore:
Documentation is not just content. It is a knowledge system.
Technical writers are uniquely qualified to:
Define concepts clearly
Establish boundaries and intent
Model relationships humans understand intuitively
Ontologies make that expertise visible and strategic.
See also: What Is Ontology-Grounded Retrieval-Augmented Generation?
What An Ontology Is Not
An ontology is not:
A style guide
A glossary (though it may reference one)
A CMS configuration
A single diagram created once and forgotten
An ontology is a living semantic contract between:
Content
Tools
AI systems
Humans
When Do You Need An Ontology?
You especially need an ontology if:
Your products are modular or platform-based
You support multiple versions simultaneously
You are building or buying AI assistants
Your documentation feeds chatbots or copilots
Consistency and trust matter
If AI is now the front door to our documentation, an ontology is the lock that keeps the wrong answers out.
The Takeaway For Tech Writers
In technical documentation, an ontology answers the hardest question of all:
“What does this actually mean — and what is it allowed to mean?”
Writers who help define and govern ontologies shape how:
Content is retrieved
Answers are generated
Products are understood
As AI becomes the voice of your documentation, ontologies decide whether that voice is informed — or improvising.
And improvisation is not a strategy. 🤠
What Makes a Topic a Good DITA Topic?
A DITA topic is a small, self-contained unit of information designed to answer one specific user need. Not a chapter. Not a page. Not a long narrative. One purpose. One job.
If you remember nothing else, remember this: DITA topics exist to do one thing for one user intent — clearly, consistently, and reuse-ready. 🧐
That single idea explains why DITA works so well at scale and why it behaves differently from traditional document-centric authoring.
See also: What is the Darwin Information Typing Architecture (DITA)?

What Makes a Topic a Good Topic?
A DITA topic is effective when it meets these criteria:
Single intent — It answers one question or supports one task
Self-contained — It makes sense without relying on surrounding prose
Context-aware — Metadata defines product, version, audience, and conditions of use
Reusable by design — It can appear in multiple documents without rewriting
If a piece of content reads awkward when reused, it probably wasn’t written as a true topic.
Why DITA Topics Exist
Before DITA, most technical documentation followed a document (book) model:
Long manuals
Linear chapters
Content written once, reused by copy-paste
Updates scattered across multiple files
That model breaks down when you need to:
Reuse content across products and versions
Publish to multiple outputs (PDF, web, help systems, chatbots)
Keep information accurate over time
Support automation, search, and AI
DITA flips the model. Instead of starting with a document, you start with topics.
The Three Core Types of DITA Topics
Most DITA implementations rely on three foundational topic types. Each enforces intent.
1. Concept Topics — “What is this?”
Concept topics explain ideas, principles, or background information.
Examples:
What a feature does
Why a setting exists
How a system behaves
They help users understand before they act.
2. Task Topics — “How do I do this?”
Task topics walk users through steps to complete a goal.
Characteristics:
Clear goal
Prerequisites
Ordered steps
Expected results
They answer action-oriented questions and work especially well for procedural content and automation.
3. Reference Topics — “What are the details?”
Reference topics provide structured facts.
Examples:
Parameters
Commands
Error codes
Field definitions
They prioritize accuracy, consistency, and scannability over narrative flow. 🤠
To Those Who Fired (or Didn't Hire) Tech Writers Because of AI
Guest post by: Fabrizio Ferri-Benedetti
Hey you,
Yes, you, who are thinking about not hiring a technical writer this year or, worse, erased one or more technical writing positions last year because of AI.
You, who are buying into the promise of docs entirely authored by LLMs without expert oversight or guidance.
You, who unloaded the weight of docs on your devs’ shoulders, as if it was a trivial chore.
You are making a big mistake. But you can still undo the damage.

It’s been a complicated year, 2025. When even Andrej Karpathy, one of OpenAI’s founders, admits, in a fit of Oppenheimerian guilt, to feeling lost, you know that no one holds the key to the future. We flail and dance around these new totems made of words, which are neither intelligent nor conscious, pretending they can replace humans while, in fact, they’re glorified tools.
You might think that the plausible taste of AI prose is all you need to give your products a voice. You paste code into a field, and something that resembles docs comes out after a few minutes. Like an anxious student, eager to turn homework in, you might be tempted to content yourself with docs theatre, thinking that it’ll earn you a good grade. It won’t, because docs aren’t just artifacts.
“You keep using that word. I do not think it means what you think it means.”

When you say “docs”, you’re careful to focus on the output, omitting the process. Perhaps you don’t know how docs are produced. You’ve forgotten, or perhaps never knew, that docs are product truth; that without them, software becomes unusable, because software is never done, is never obvious, and is never simple.
When AI Becomes the Search Interface, Structure Becomes the Advantage
Search is no longer about links
Technical writers are watching the same shift everyone else is watching: search engines are turning into AI-driven answer engines. Instead of sending users to web pages or help sites, these systems increasingly synthesize and deliver answers directly inside search results pages and chat interfaces.
For publishers who depend on referral traffic 📈, this raises alarms. For technical writers, it raises a different — and potentially more interesting — question:
If AI systems are now the primary readers of our content, are we writing in a way machines can actually understand?

Uncomfortable Truth: AI Can’t Make Sense of Unstructured Content Blobs
Large language models perform best when they can identify intent, scope, constraints, and relationships. Unstructured prose forces them to guess. That guessing shows up as hallucinations, incomplete answers, or advice taken out of context.
👉🏾 PDFs, long HTML pages, and loosely structured markdown were designed for human reading, not machine reasoning.
They obscure:
What task the user is trying to complete
Which product version applies
What prerequisites or warnings matter
Whether an instruction is conceptual guidance or procedural truth
When AI search engines ingest this kind of content, they flatten it. The result they provide may sound fluent, but it’s dangerously lacking in the precision department.
The Real Issue Isn’t AI — It’s Accountability
In AI and Accountability, Sarah O’Keefe argues that organizations are chasing the wrong goal with generative AI in content creation. Many businesses describe success as producing “instant free content,” but that’s a flawed metric. The true organizational goal isn’t volume of output — it’s content that supports business objectives and that users actually use.
AI Produces Commodity Content
O’Keefe points out that:
Content is already treated as a commodity in many marketing teams
Generative AI excels at producing generic, average content quickly
That’s fine for low-level output (but it doesn’t create quality, accurate, domain-specific content on its own)
When the goal is high-value content, simply doing “more” with AI fails
O’Keefe mirrors broader industry cautions that AI is very good at pattern synthesis but struggles with original, accurate, context-aware creation without structured inputs.
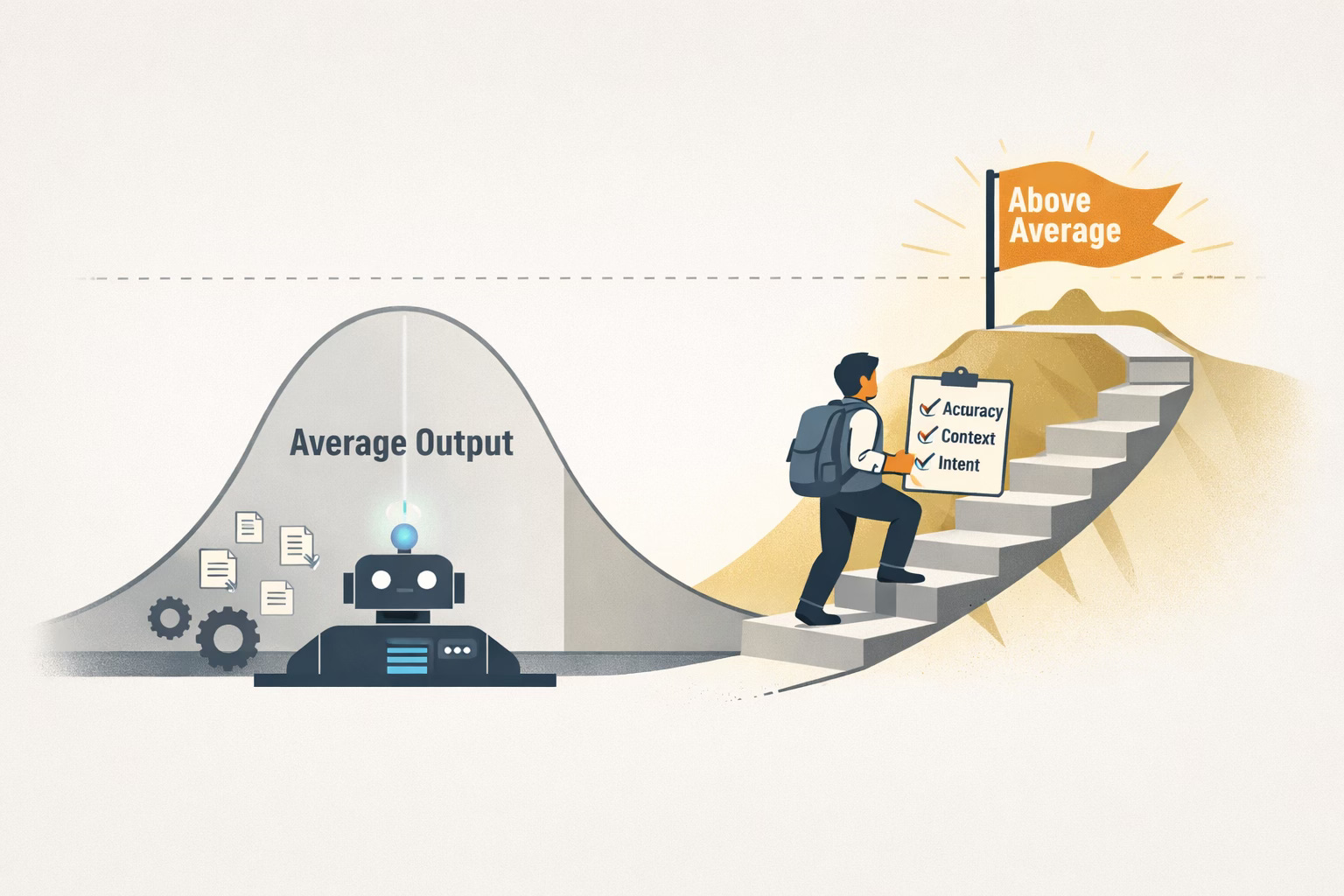
AI Can Raise Average Quality — But It Won’t Raise Above Average
O’Keefe emphasizes that:
If your current content is below average, AI might improve it
If your content needs to be above average, generative AI does not reliably get you there without expert oversight
This performance gap stems from how AI models generate outputs — they produce the statistical average of what they’ve been trained on
This is an important distinction for tech writers whose docs must be precise, technically correct, and trustworthy.
Accountability Doesn’t Go Away With AI
A central theme is: authors remain accountable for the accuracy, completeness, and trustworthiness of content they publish, regardless of whether AI assisted in generating a draft. O’Keefe gives practical examples:
AI can article-spin but still generate bogus reference
AI won’t justify legal arguments or identify critical edge cases
Errors from AI are still your responsibility if you publish the content
This has real implications for technical documentation where accuracy and liability matter.

The Hype Cycle Isn’t Strategic
O’Keefe warns that focusing internally on “how heavily we’re using AI” is a hype-driven metric, not a strategic one. Tech writers and content leaders should reframe the conversation:
From “how much AI are we using?”
To “how efficient and reliable is our content production process?”
To “how good is the content we deliver for its intended use?”
This shift helps teams build accountability into their workflows instead of chasing novelty.
What This Means for Tech Writers
For tech writers specifically, here are the distilled takeaways:
AI should be a tool — not the goal: Use AI to handle repetitive, well-defined tasks, while keeping humans responsible for correctness and intent
Focus on quality over quantity: Audiences value clarity and accuracy more than volume
Maintain author accountability: Even when AI suggests or drafts content, the author still owns the final product’s correctness and accuracy, especially for technical and regulated content
Measure impact, not usage: Shift performance evaluation from AI adoption rates to content effectiveness and user outcomes
👉🏾 Read the article. 🤠
Gilbane Advisor 1-28-26 — Reusing content, AI bot swarms
2026 State of AI in Technical Documentation Survey
The Content Wrangler and Promptitude invite you to participate in our 2026 State of AI in Technical Documentation Survey, a five-minute multiple-choice survey that aims to collect data on where AI appears in documentation workflows, which tasks it supports, how often it is used, and the challenges that limit broader adoption.
We also seek to understand organizational support, tooling gaps, and where documentation professionals believe AI could deliver the most value in the future.

After the survey closes, we will analyze the results and publish a summary report highlighting the trends, patterns, and shared challenges across the industry. The goal is to provide documentation leaders and practitioners with credible data to guide decisions, advocate for better tools and training, and set realistic expectations for AI’s role in technical documentation.
Complete the survey and provide a valid email address to receive a copy of the final survey results report via email shortly after the survey closes.
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Discover How Semantic Structured Content Powers AI Solutions at DITA Europe 2026

It’s not too late! I hope you'll join me in Brussels at Hotel Le Plaza Brussels, February 2-3, 2026, for DITA EUROPE 2026 — the conference for technical writers and information developers looking to build advanced information management and delivery capabilities. If your technical documentation team produces content using the Darwin Information Typing Architecture (DITA) — or you’re considering doing so‚ this is the conference for you.
👉🏼 Grab your tickets now! Save 10% off the cost of registration using discount code — TCW — at checkout.
I’ll be delivering a talk with Dominik Wever, CEO of Promptitude — Powering AI and Virtual Humans with DITA Content — during which we’ll show how we built an AI-powered bot that delivers trustworthy, contextually accurate answers using technical documentation authored in DITA XML. Then, we’ll take it a step further—layering an interactive video agent (a virtual human) on top of the bot to create an engaging, human-like interface for delivering content.
Attendees will learn why structured content is essential for powering intelligent systems, how to responsibly connect DITA to AI models, and what opportunities virtual humans offer for technical communication. Whether you’re curious about future-ready documentation practices or looking for practical ways to extend the value of your content, this talk will offer both inspiration and concrete lessons.
DITA Europe is brought to you by the Center for Information Development Management (CIDM) — a membership organization that connects content professionals with one another to share insights on trends, best practices, and innovations in the industry.
CIDM offers networking opportunities, hosts conferences, leads roundtable discussions, and publishes newsletters to support continuous learning. CIDM is managed by Comtech Services, a consulting firm specializing in helping organizations design, create, and deliver user-focused information products using modern standards and technologies.
Day One: February 2, 2026
A large portion of Day 1 focuses on how AI actually behaves when it meets real-world documentation systems and legacy content — warts and all.
Key focus includes:
AI benefits and failure modes in real-world use
Aligning AI output with style guides and editorial standards
Enhancing AI results through better context, tools, and editing workflows
Deploying documentation directly to AI systems (not just to humans)
February 2 sessions emphasize that AI quality is constrained by content structure, governance, and determinability:
AI in the Real-World: For Better and Worse — Lief Erickson
Win Your Budget! — Nolwenn Kerzreho
AI + DocOps = SmartDocs — Vaijayanti Nerkar
DITA in Action: Strategies from Real-World Implementations — Maura Moran
Determinability and Probability in the Content Creation Process — Torsten Machert
From Binders to Breakthroughs: Cisco Tech Comms’ DITA Journey — Anton Mezentsev & Manny Set
Enhancing AI Intelligence: Leveraging Tools for Contextual Editing — Radu Coravu
From SMB’s to Enterprises: Real-World Content Strategy Journeys — Pieterjan Vandenweghe and Yves Barbion
Aligning AI Content Generation with Your Styleguide — Alexandru Jitianu
A Transition From One CCMS to Another – Lessons Learned — Eva Nauerth and Peter Shepton
Cutting the Manual Labor: Scaling Localized Software Videos — Wouter Maagdenberg
Revolutionizing Docs: DITA, Automation & AI in Action – Akanksha Gupta
Future of Documentation Portals: From DevPortal to Context Management System — Kristof Van Tomme
How AI is Boosting Established DITA Localization Practices — Dominique Trouche
Trust Over Templates: Skills That Make A Content Transformation Work — Amandine Huchard
Powering AI and Virtual Humans with DITA Content — Scott Abel
DITA 2.0 + Specialization Implementation at ALSTOM — Thomas Roere
Deploying Docs to AI — Patrick Bosek
I’d Like Mayo With That: Our Special Sauce for DTDs — Kris Eberlein
Day Two: February 3, 2026
Transforming Customer Support Through Intelligent Systems — Sharmila Das
DITA and Enterprise AI — Joe Gollner
Agentic AI: How Content Powers Process Automation — Fabrice Lacroix
Why DITA in 2026: The AI Age of Documentation — Deepak Ruhil and Ravi Ramesh
Content Automation 101: What to Automate and What Not To — Dipo Ajose-Coker
Empowering DITA with Standards for AI in Safety-Critical Areas — Martina Schmidt and Harald Stadlbauer
Taxonomy For Good: Revisiting Oz With Taxonomy-Driven Documentation — Eliot Kimber and Scott Hudson
Upgrading the DITA Specification: A Case Study in Adopting 2.0 — Robert Anderson
Hey DITA, Talk To Me! How iiRDS Graphs Infer Answers — Mark Schubert
The Secret Life of Technical Writers: Struggles, Sins, and Strategies — Justyna Hietala
Better Information Retrieval in Bringing DITA, SKOS, iiRDS Together — Harald Stadlbauer, Eliot Kimber, Mark Schubert
If They Don’t Understand, They Can’t Act: Comprehension in DITA — Jonatan Lundin
DITA, iiRDS, and AI Team Up for Smart Content Delivery — Marion Knebel, Gaspard Bébié-Valérian
Pretty As a Screenshot: Agile Docs Powered by QA Tools — Eloise Fromager
Bridging the Gap – Connect DITA, Multimodal Data via iiRDS — Helmut Nagy, Harald Stadlbauer
Guardrails for the Future: AI Governance and Intelligent Information Delivery — Amit Siddhartha
Highly Configurable Content using DITA, Knowledge Graphs and CPQ-Tool — Karsten Schrempp
Building a Content Transmogrifier: Turning Reviews into Something Better — Scott Hudson, Eliot Kimber
👉🏼 Grab your tickets now! Save 10% off the cost of registration using discount code — TCW — at checkout.
The Content Wrangler is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
The best way to talk about AI: don't say 'AI' so much; say what you really mean
Verndale acquires the Product Experience Division of Amp
Search
Recent Content
- Forum for DITA Users
1 year ago - Publishing for DITA
6 years ago - Optimizing the DITA Authoring Experience — Online Course
6 years ago - Linking to another chunked topic
6 years ago - Advanced Reuse Strategies — Online Course
7 years ago - 2019 Content Management Strategies/DITA North America Conference
7 years ago




